Michael Beveridge
TrackMatch & Micro-Set Playlist Apps
Music has been central to my life since my teens. Over the years I’ve built a high-resolution library of more than 30,000 songs — albums I’ve purchased directly to support artists and preserve recordings not found on streaming services. It’s an archive I return to daily, and it’s the foundation for this project.
The Problem
I began asking why some songs “fit” together so well, the way a DJ can move between genres seamlessly. Recommendation engines promise to solve this, but their results are predictable and tied too closely to genre or popularity. I wanted to flip the model: instead of starting with a theme, start with a single track and find others that sounded alike based on audio traits.
My First Attempt & Early Learnings
My first experiment used Spotify’s audio features — tempo, key, energy, valence — mapped against my library. With ChatGPT’s help I reconciled metadata and tested matches. It worked in small bursts but quickly broke down: the AI stalled, hallucinated, or lost track of parameters. The lesson was clear: automation alone wasn’t enough — human taste and curation mattered more.
These early attempts highlighted two gaps. Spotify’s data covered only ~85% of my library, and relying on an LLM to do the analysis simply didn’t work. Models weren’t trained on this dataset, and they struggled to prioritize attributes or keep context. What started as a music experiment became an exploration of how to work with AI effectively.
This was the turning point: I stopped asking AI to analyze the music for me and started working with it as a research assistant and coding partner. Together we built the scripts to scan my collection and capture richer features — the foundation for the app.

Data Capture
To move forward, I needed a complete dataset I could trust. Spotify’s attributes were valuable, but with gaps across 10–15% of my library, they weren’t enough to analyze the whole collection. The solution was to scan the music directly. Using Essentia and Python scripts developed with ChatGPT, I processed my lossless library once, logging errors and skipping already-scanned tracks to keep the workflow efficient while ensuring near-total coverage.
The result was a set of 20 distinct audio features for every track. Stored in a local database I could search instantly, this became the foundation for an app that could compare songs based on how they actually sound.
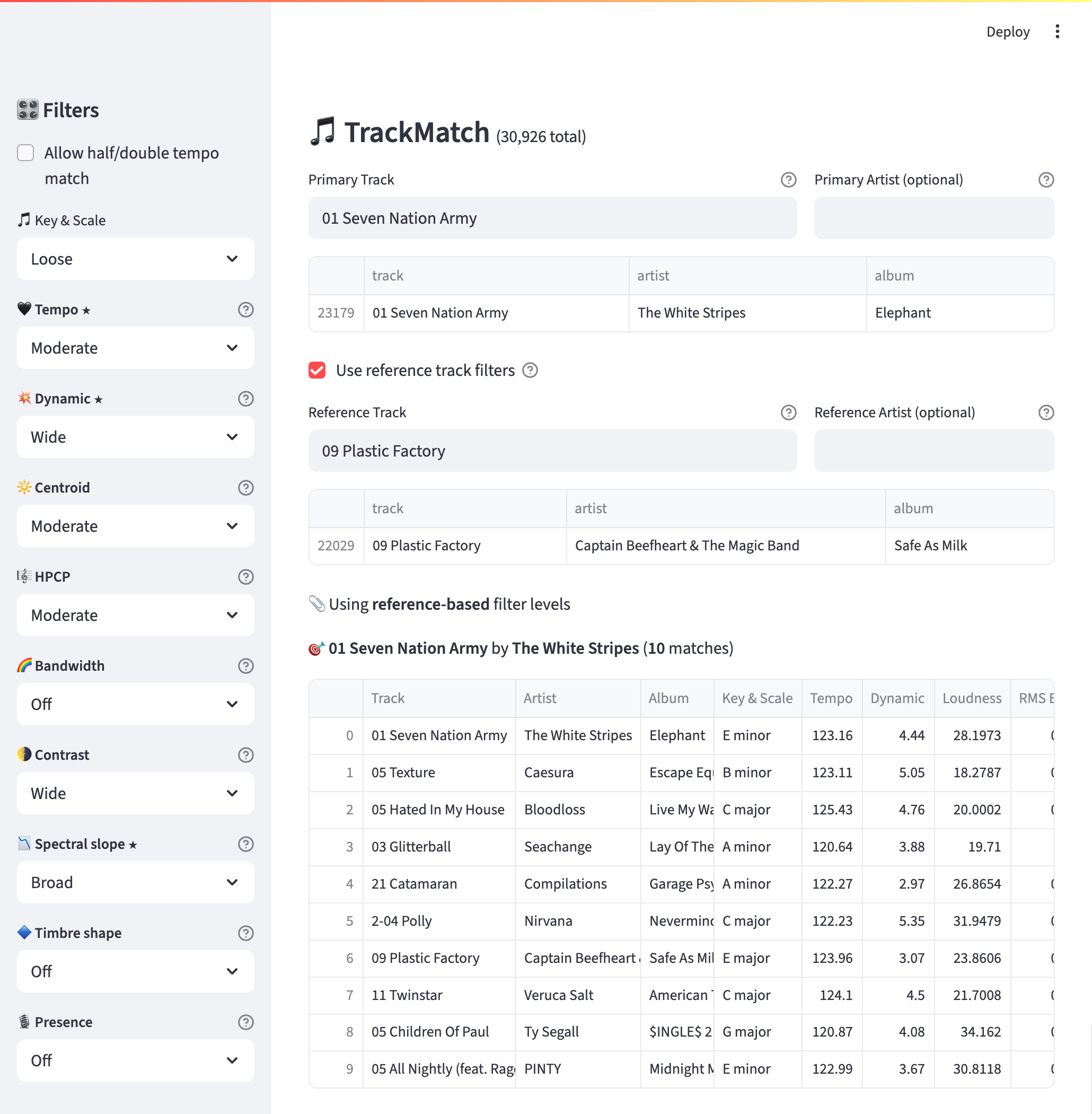
TrackMatch App
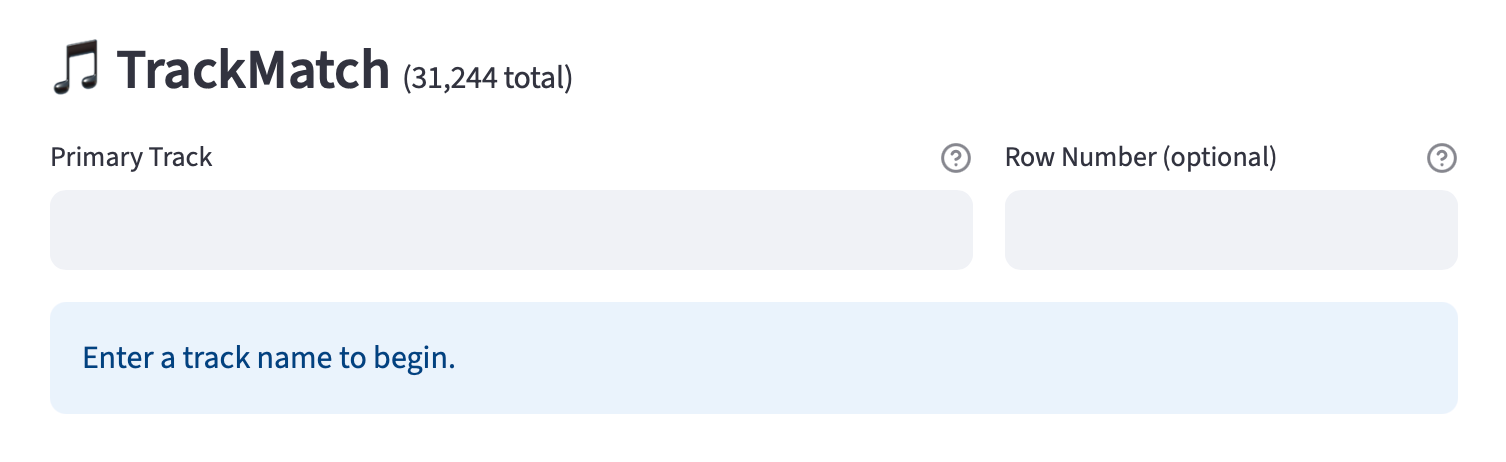
Streamlit App Design
The app was designed for speed and predictability. With a local database and precomputed features, results appear in seconds. The same inputs always produce the same outputs — no randomness, no hidden bias. AI automated the heavy lifting, but the process stays human-in-the-loop: I choose the seed track, adjust the constraints, and curate the final outcome.
Filters as Musical Levers
Filters became the app’s core UX pattern. Each seed track starts with smart defaults, informed by its own audio profile, so I see useful results immediately. From there I can add or remove attributes to filter on, adjust parameters to be narrower or broader, and even introduce a reference track, shifting the focus toward features the two songs share. This makes exploration fast while still giving me precise control when I need it.
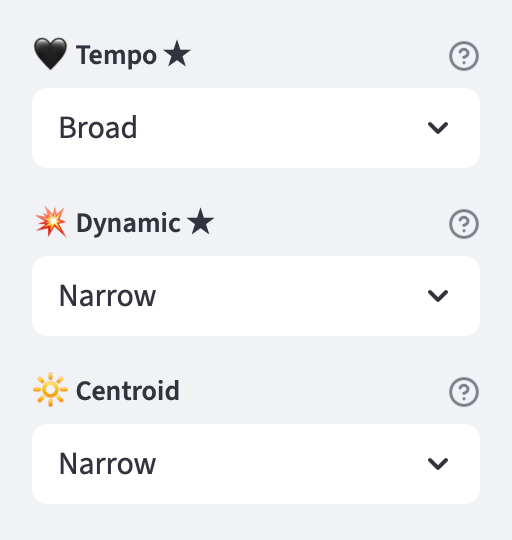
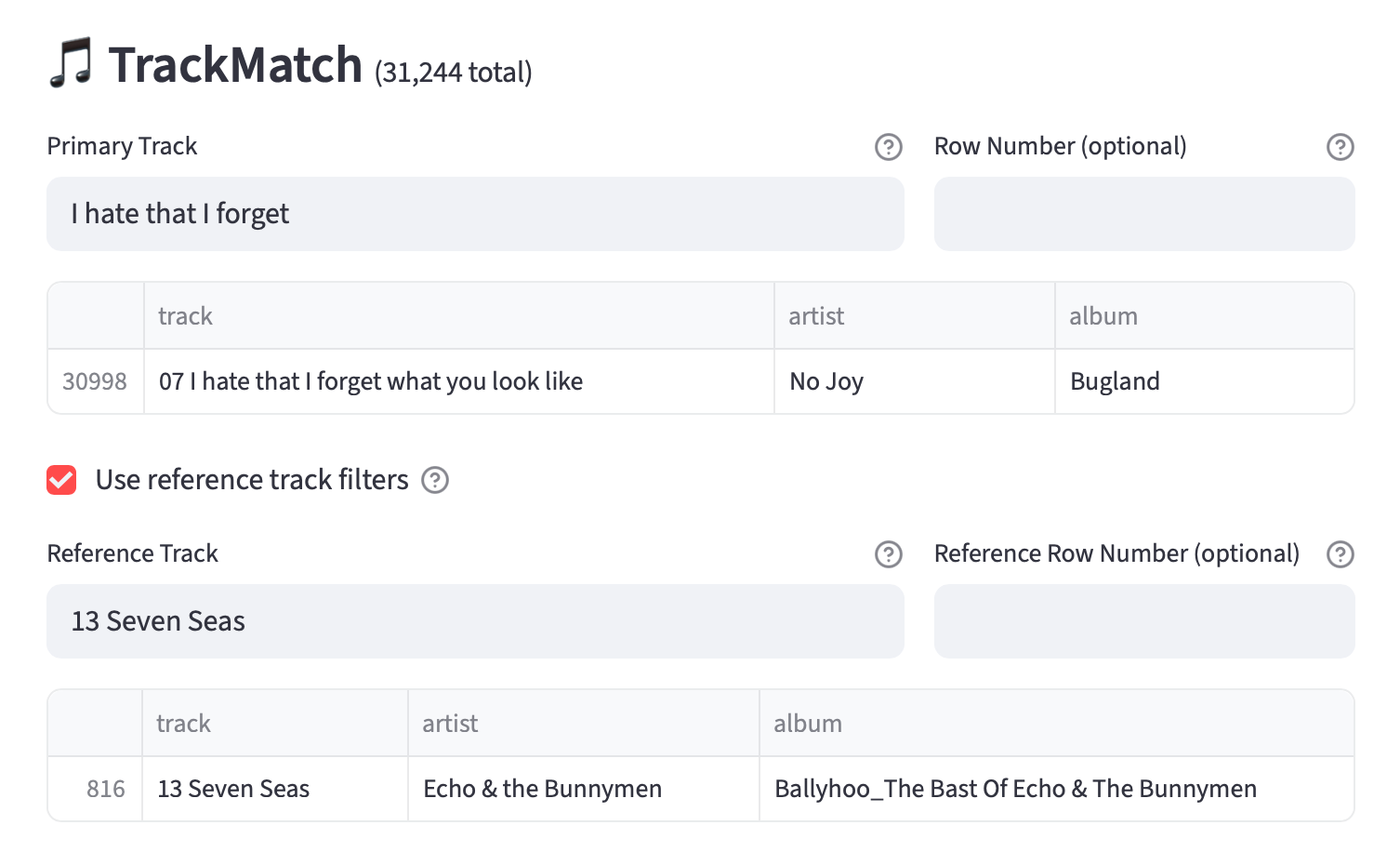
Key + Scale Matching
Western music follows some simple harmonic rules that tell us which keys and scales tend to sound good together. I built a key+scale filter that applies those rules, so I can choose whether matches need to be exact, harmonically compatible, or more loosely related. What makes this filter unique is how it ties the math of frequency to the emotion of music: two songs might share the same tempo, loudness, and dynamics, but if one is in a joyful major key and the other in a brooding minor key, they won’t feel alike at all. The key+scale filter bridges that gap, ensuring similarity isn’t just technical but musical.

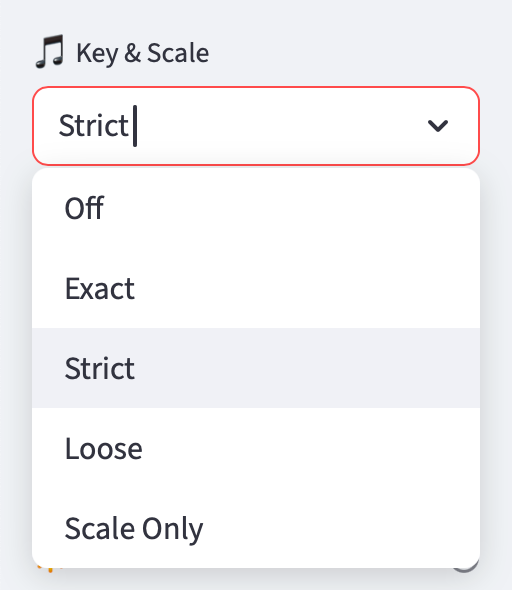
Workflow in Practice
A typical session takes just a few minutes. I’ll pick a seed track, adjust filters until I’m down to a short list of candidates, and audition a few in Roon. From there I complete a three-song micro-set — the core building block of this project. Because the filters are deterministic and tuned to their attributes, the same inputs always yield the same outputs, which makes iteration fast and easy to trust. What’s interesting is that I can restart with the same seed, change the filters, and end up with an entirely different set. That flexibility makes the tool as much about discovery and creativity as it is about matching.
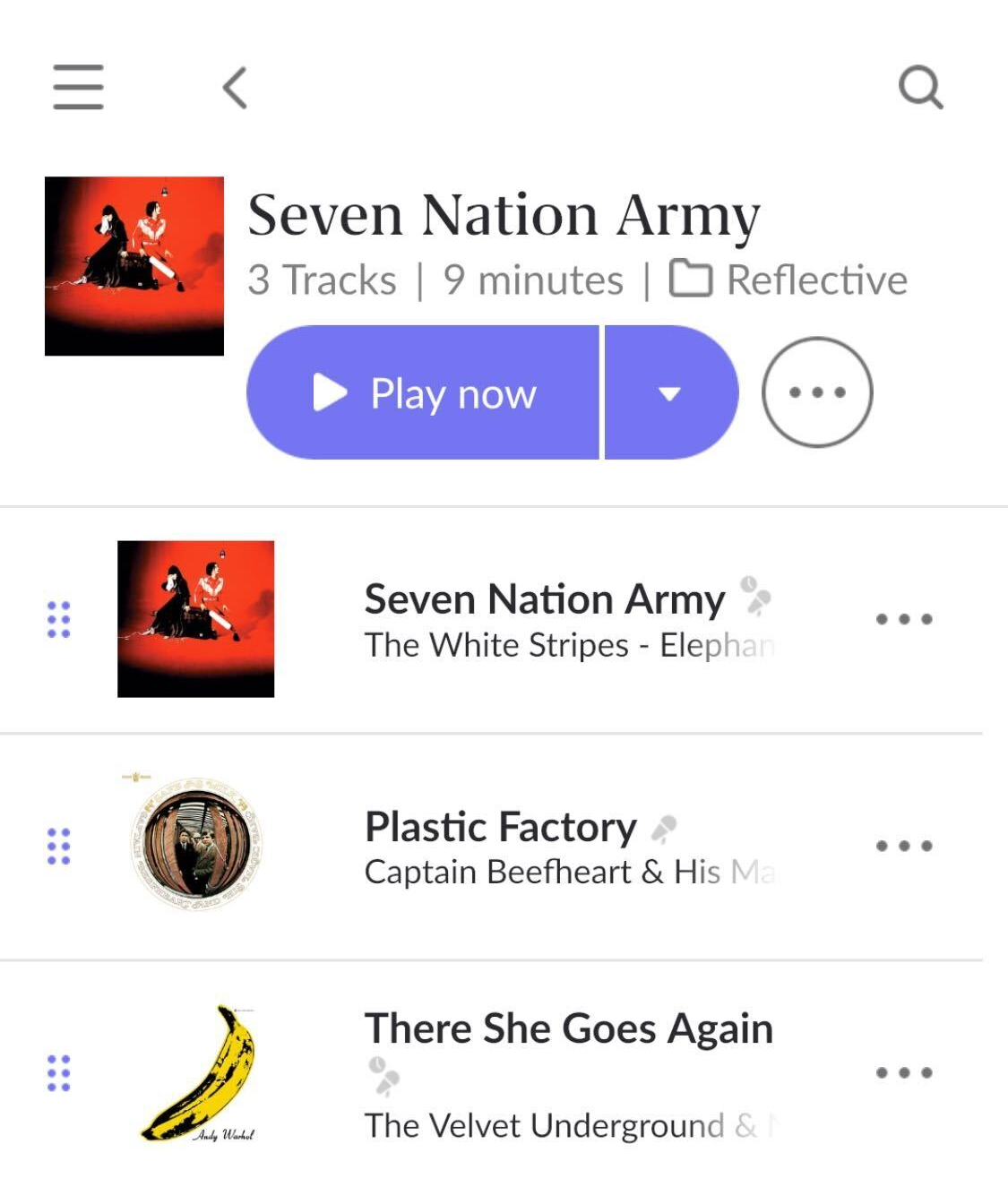
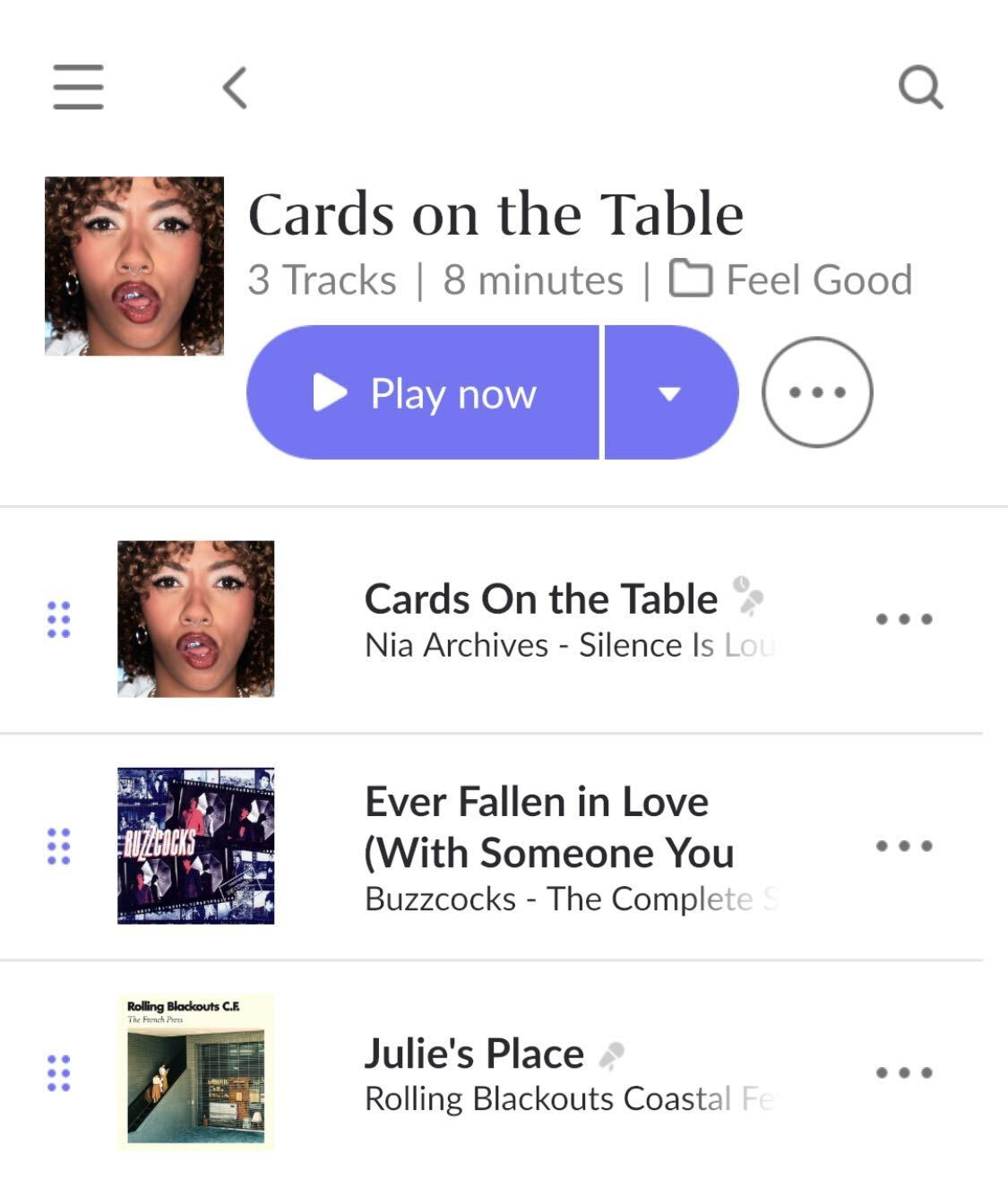
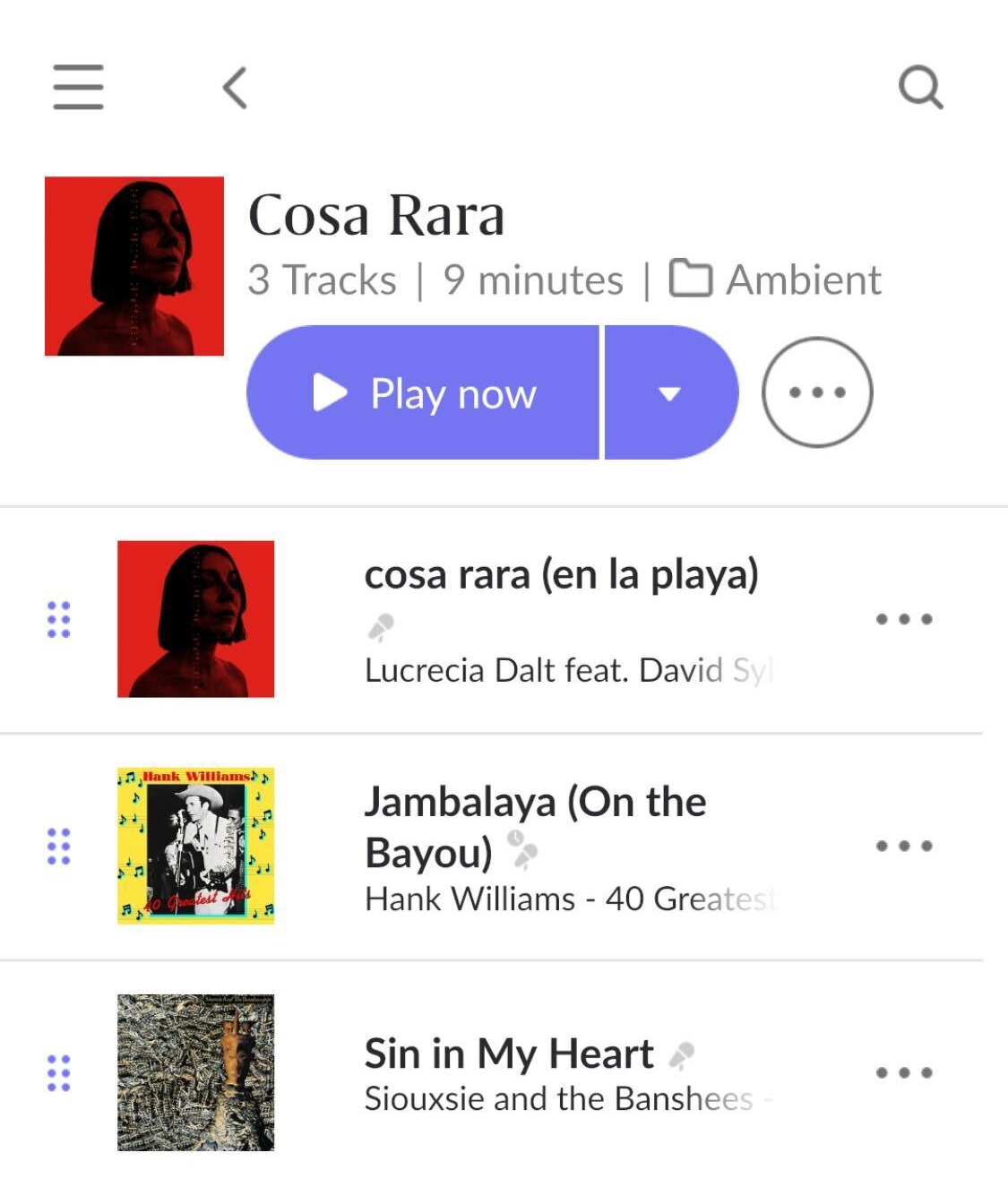
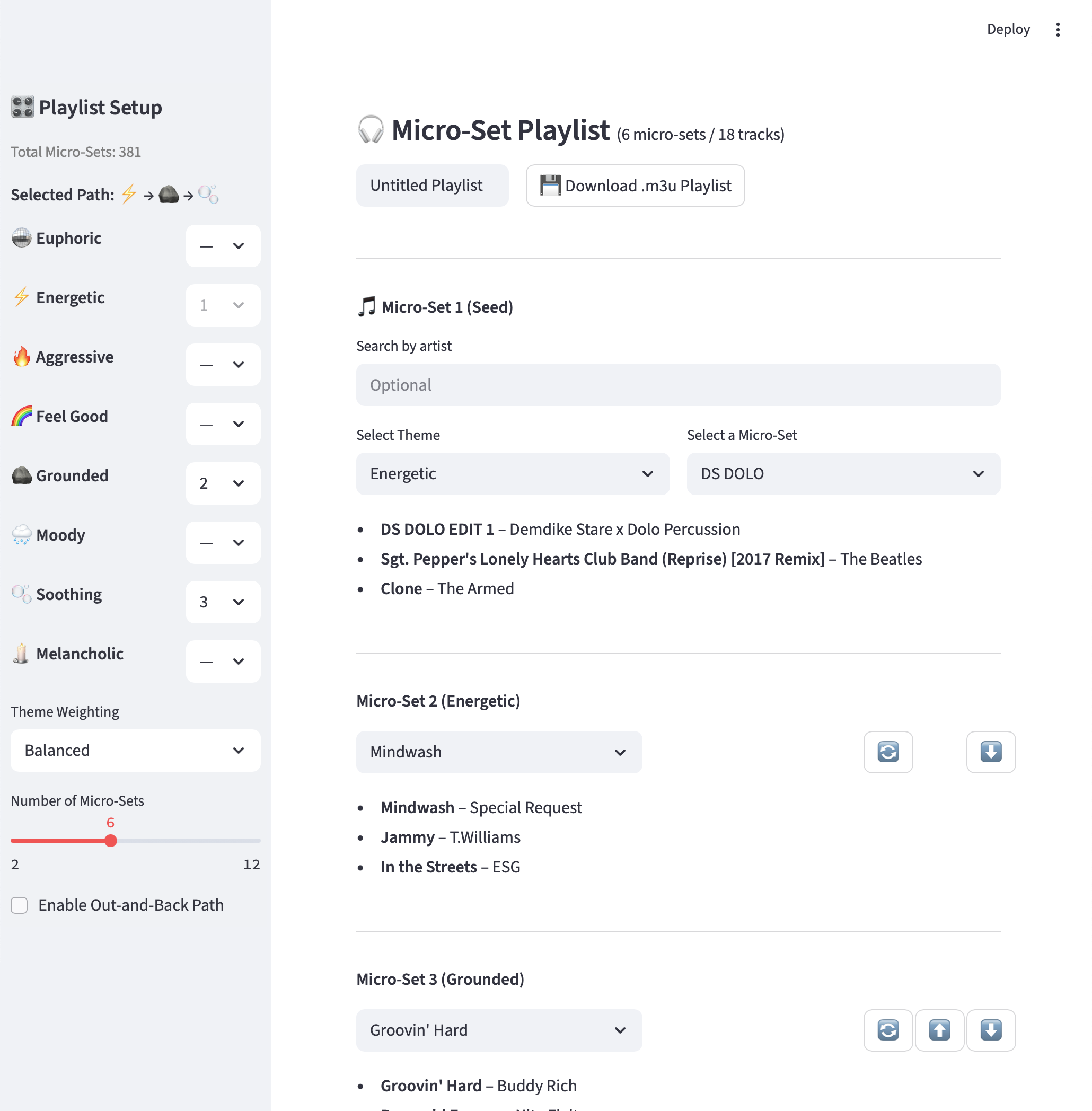
Micro-Set Playlist App

From Songs to Micro-Sets
TrackMatch helped me identify three-song clusters that felt cohesive. Each set became a single unit: small enough to stand on its own, but flexible enough to string together into longer listening experiences. The playlist app was built around this concept: instead of sequencing individual tracks, it works with micro-sets as the core building blocks.
Defining Themes
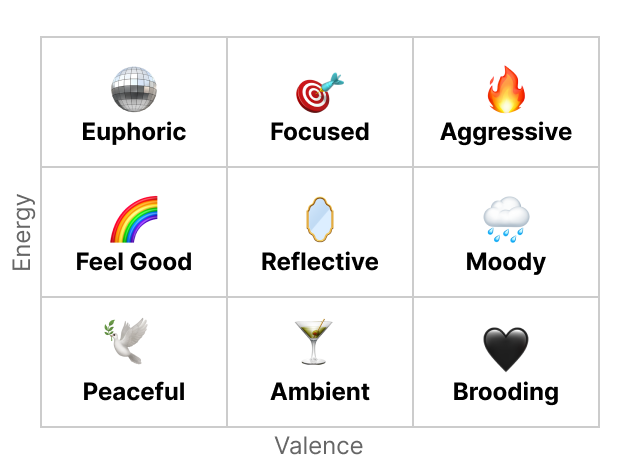
To make sense of hundreds of micro-sets, I grouped them into themes using a simple energy × valence model. On paper, this meant a nine-cell grid; in practice, it resolved into a smaller set of categories, ranging from calm and grounded to euphoric and aggressive. This gave each micro-set a clear identity and provided the structure needed to build playlists with direction.
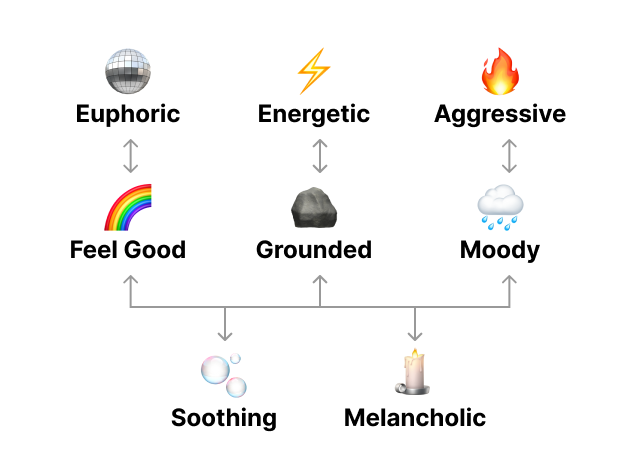
Paths, Weights, and Flow
Once the themes were defined, I needed a way to move through them. The app uses “paths” — sequences of themes that shape the emotional arc of a playlist. Weights let me control emphasis (front-loaded, back-loaded, or balanced), while an out-and-back option adds symmetry by circling back toward the starting theme. Combined with simple rules like avoiding duplicate artists, this system produces playlists that feel intentional, with a sense of momentum and return.

Bringing It Together
In practice, the generator can create hours-long playlists that trace a clear emotional journey while still leaving room for surprise. The result feels less like an algorithm and more like a curated set, built from small, reliable building blocks but shaped by larger patterns of energy and mood.
Spotify examples: Positive Ramp, Negative Ramp
Reflections
These projects reminded me that AI isn’t here to replace creativity — it’s here to support it. I didn’t use ChatGPT as an oracle; I used it as a partner. It helped me research, structure, and code, but I made the choices about what to pursue and how to shape the outcome. The best results came when I combined its speed with my own curiosity and taste. That balance — AI as assistant, human as creator — is what made the work possible.